Documents processing
Intelligent document processing concept
Intelligent Document Processing is a quality driven process which is controlled by elDoc system by analyzing confidence levels (per-character) of the retrieved data, e.g.: documents scanned with a good quality provide results with a high confidence levels whereas documents of the low scanned quality or with artifacts like remarks over printed text may provide results with low confidence levels.
- Intelligent Document Processing is performed automatically leveraging cognitive technologies to achieve the greatest recognition results. Once document is processed - it is placed either to Archive / Repository directory or Inbox directory.
- Archive / Repository directory: documents are placed into this directory automatically following principle STP (Straight Through Processing) under the following conditions:
- the document was classified by matching required RecoForm;
- all defined fields are located in the document;
- data in the fields is recognized with sufficient confident level set as the threshold.
- Inbox directory: document are placed into this directory under the following conditions:
- the document was NOT classified by matching required RecoForm;
- NOT all defined fields are located in the document;
- data in the fields is NOT recognized with sufficient confident level set as the threshold.
- Documents which are placed into the Inbox directory require validation (See: Documents validation)
Multi-page and multi-documents files processing
elDoc system supports processing of the multi-page document files processing as well as multi-page & multi-documents files processing.
Example: PDF file contains 4 pages:
- pages 1 and 2 represent two-pages Invoice;
- pages 3 and 4 represent two-pages Purchase Order.
For such and similar scenarios elDoc system is able to recognize both documents (Invoice and Purchase Order) as well as retrieve data from respective pages of different documents.
Multi-document Recognition document interface provides the following two main areas:
- Area 1 - represents common information related to the Recognition document and uploaded (source) file. This are also shows common fields defined on the Recognition form level
- Area 2 - represents fields (Recognition data) retrieved for the specific document inside multi-document file (PDF or TIFF files could contain several pages).
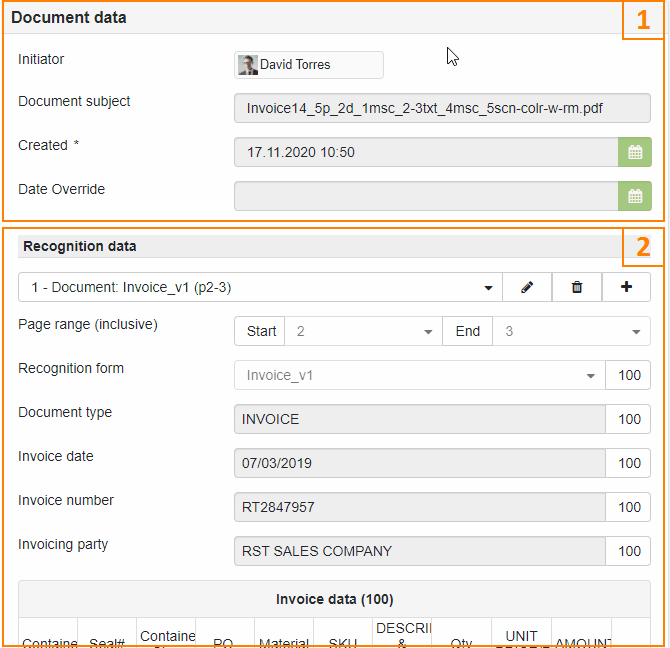
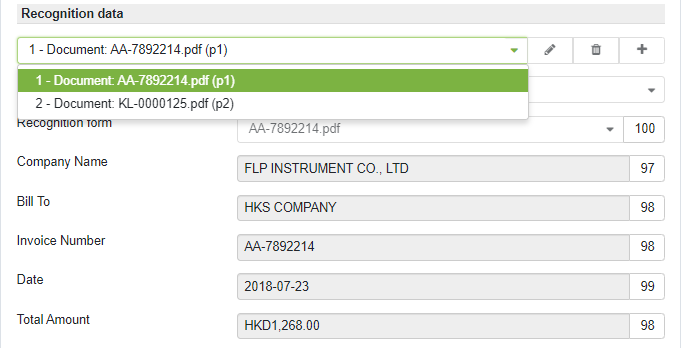
To switch between different documents on the user interface use the respective selector in Recognition data area. Recognition data (extracted from the source document) is displayed in respective fields.
Last modified: July 16, 2024