Recognition results post-processing
In various scenarios, the captured recognition data may need additional post-processing to prepare, clean, or validate the data further. For instance, in cases such as invoices where the sum of line items should match the total invoice amount, elDoc's IDP & BPM system provides robust post-processing capabilities.
The post-processing functionality utilizes a JavaScript script engine, meaning that standard JavaScript syntax is used for writing the post-processing code. This allows for flexible and powerful data manipulation and validation.
Post-processing can be applied both to specific fields and to the entire RecoForm, enabling precise and comprehensive handling of document data.
Code repository
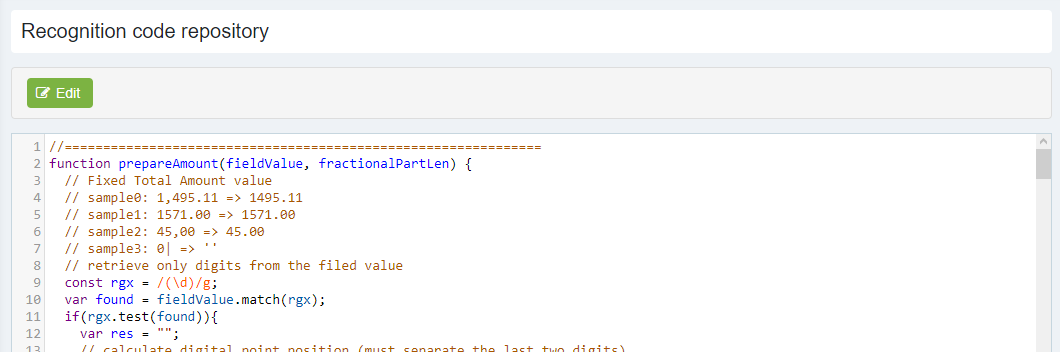
Post-processing code repository is provided for storing codes (functions) which are to be shared across different fields and RecoForm post-processing code snippets. Code repository is accessible via the Recognition rules management page by pressing Code repository button.
Important:
- on RecoForms export - whole code repository contents is being exported and saved within RSF-file;
- on RecoForms import - codes are being imported and appended to the existing code repository. Imported codes are appended after the following divider:
//
// Imported by RFS-import on: 17.06.2021 08:26
//
Bitap support in post-processing
Due to the inherent challenges of using OCR for data recognition, some words may come with apparent mistakes. To address such issues automatically, elDoc provides built-in support for basic Bitap operations in post-processing, enhancing the accuracy of recognized data.
The following functions are supported in post-processing:
/** * Replaces searchValue in originalValue with searchValue if case it was found with the defined (by mistakesCount) maximum of allowed mistakes * * originalValue - string value containing one or several words * searchValue - string value for search * mistakesCount - integer value indicating the maximum number of allowed mistakes **/ Bitap.replace(originalValue, searchValue, mistakesCount); /** * Replaces searchValue in originalValue with newValue if case it was found with the defined (by mistakesCount) maximum of allowed mistakes * * originalValue - string value containing one or several words * searchValue - string value for search * mistakesCount - integer value indicating the maximum number of allowed mistakes * newValue - string value to be used for replacing found value **/ Bitap.replace(originalValue, searchValue, mistakesCount, newValue); /** * Returns index of first occurrence of searchValue in originalValue in case it was found with the defined (by mistakesCount) maximum of allowed mistakes * * originalValue - string value containing one or several words * searchValue - string value for search * mistakesCount - integer value indicating the maximum number of allowed mistakes **/ Bitap.indexOf(originalValue, searchValue, mistakesCount); /** * Returns boolean value true|false indicating whether originalValue contains searchValue with the defined (by mistakesCount) maximum of allowed mistakes * * originalValue - string value containing one or several words * searchValue - string value for search * mistakesCount - integer value indicating the maximum number of allowed mistakes **/ Bitap.contains(originalValue, searchValue, mistakesCount);
Notes relevant to all Bitap functions:
- Minimal length of the original string value should be equal or longer than 5 characters;
- Minimal number of allowed mistakes is 1. Maximum number is calculated based on the word length and in case higher number is provided it is replaced with the maximum allowed. The following rules apply:
- Word length >= 5 - max. number of allowed mistakes is 1;
- Word length <= 7 - max. number of allowed mistakes is 2;
- Word length <= 10 - max. number of allowed mistakes is 3;
- Word length <= 15 - max. number of allowed mistakes is 5;
- All functions process original string value by splitting it by space into words and joining words which do not meet length criteria (maximum length for the single word can not exceed 15 characters). For example: original given string value "Pick Up / Transport Charges" is split into the following set of words:
- Pick Up
- Up / Transport
- / Transport
- Transport
- Charges
Useful code samples
/**
* Returns field index by tag or -1 in case no field found by the given tag
*/
function getFieldIndexByTag(fieldTagName, fieldsArray){
return fieldsArray.findIndex(field => field.tags.includes(fieldTagName));
}
Last modified: August 14, 2024