Recognition rules setup
elDoc IDP performs document processing using recognition rules (also referred as "Recognition form" or "RecoForm") defined in the system.
This page describes how to setup RecoForms:
Recognition form creation
You can create unlimited number of the recognition forms in the system. In order to create a new recognition form - press +Add button on the Recognition rules page.
Recognition form settings
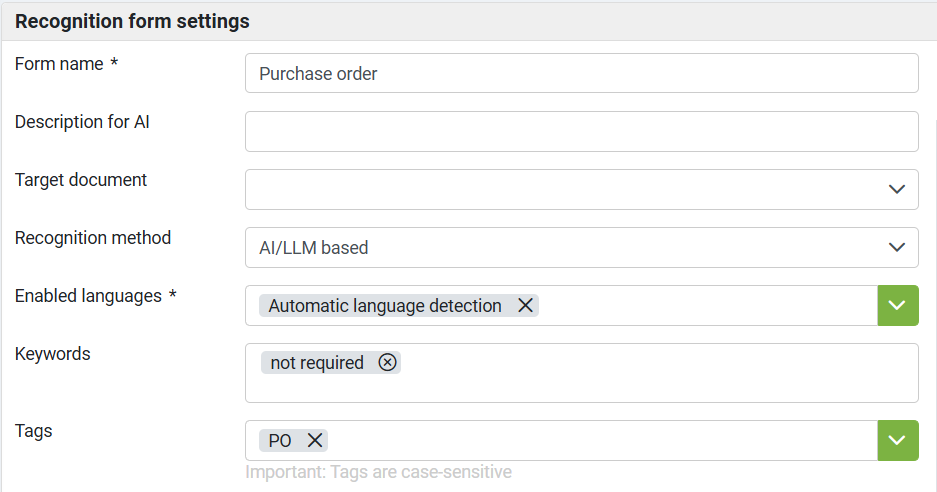
Form name (required field) - name which is distinctive and obvious for corresponding document.
NOTE: Form name should be a unique name.
Hint
It is recommended to have naming conventions for the RecoForm names in order to be able to manage RecoForms when number of them growth.
Naming convention may look as follows:
- Example for invoices: {docType}_{remarks} e.g.: Invoice_VENDOR1, Invoice_VENDOR2, etc.;
- Example for utility bills: {docType}_{provider}_{layoutType}_{remarks} e.g.: Bill_CLP_L1_en, Bill_WSD_L1_cn, etc.
This will allow to have a better manageability of RecoForms.
Description for AI - Provides a description of the document intended for AI/LLM models to accurately identify and classify this document type.
Target document (optional) - select Document type from drop-down list if it is required to perform Conversion after the document recognition is completed. If Conversion is not required, leave the field blank.
Recognition method - defines type of recognition approach to be applied for the specific RecoForm. By default it is set to "Anchor based".
- AI/LLM based - automatic document data extraction using AI/LLM models (available when AI/LLM is enabled)
- Anchor based - is recommended to apply for documents of standard layout / document with fixed table format (e.g. invoices, purchase orders, service reports, transcripts, etc).
- Regex-based - is recommended to apply for documents of not standard layout / document without fixed table format (e.g. boarding pass, payment instructions, etc).
- Custom plugin based - custom RecoForms for handling non-trivial document types.
Enabled languages – select language(s) from drop-down list to be applied during the recognition process. By default it is set to English. NOTE: When several languages are selected - the first selected language treated as the main language of the document.
Hint
Keywords (required field) - lists keywords which are associated with a particular type of the document and/or minus key words that are not associated with a particular type of the document (should be present on the page). Adding keywords and/or minus keywords to the specific RecoForm helps to optimize Recognition Queue processing. The following rules are applied during the recognition process:
- Keywords (inclusive) - listed as normal words. The rule that all keywords have to be present on the document in order to include this RecoForm into the IDP phase;
- Minus keywords (exclusive) - listed as words starting with "-" minus sign (e.g.: -invoice). In case any of the listed minus keyword is present on the document page - the given RecoForm will be excluded from the IDP phase.
Keywords also support regex when used with prefix "regex:", e.g.:
- regex:invo[i1l]ce - Regex-based keyword which handles cases like invoice, invo1ce and involce;
- -regex:invo[i1l]ce - Regex-based minus keyword which handles cases like invoice, invo1ce and involce;
Regex-based keywords follow general keywords rules and support general regular expression syntax;
Note
Tags - defines tags assigned to the RecoForm. Tags assignment helps to optimize documents processing by telling system which RecoForms should be used for the document processing. System shortlists RecoForms which contain all assigned tags on the Recognition Document (one or several) and processes document using only shortlisted by tags RecoForms.
Document sample upload
Document sample is required by RecoForm in order to define recognition rules by marking document's layout.
Hint
For getting better results during documents processing it is recommended to use document sample of the best available quality for RecoForm.
General recommendation for the document sample: it should be scanned with min. scanning resolution of 300DPI, properly aligned, do not contain artifacts, and contain only target page(s) and as few pages as possible.
1) Once new RecoForm is created you need to provide document sample which the given RecoForm will be processing by extracting its data.
- Press +Choose button to upload document sample;
- Press Remove sample button to remove attached sample.
2) Uploaded Document sample is displayed at the right side of the Recognition form page.
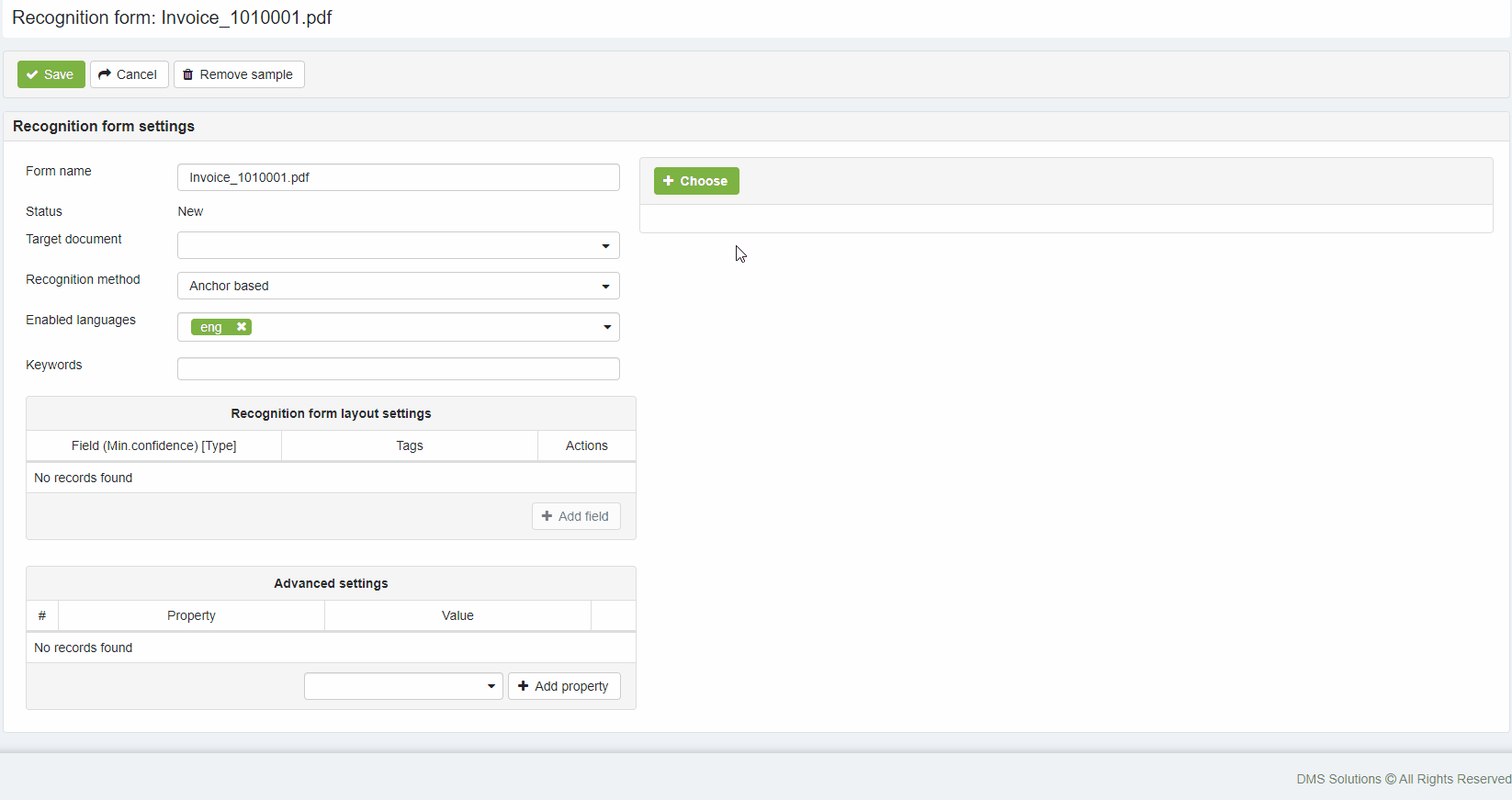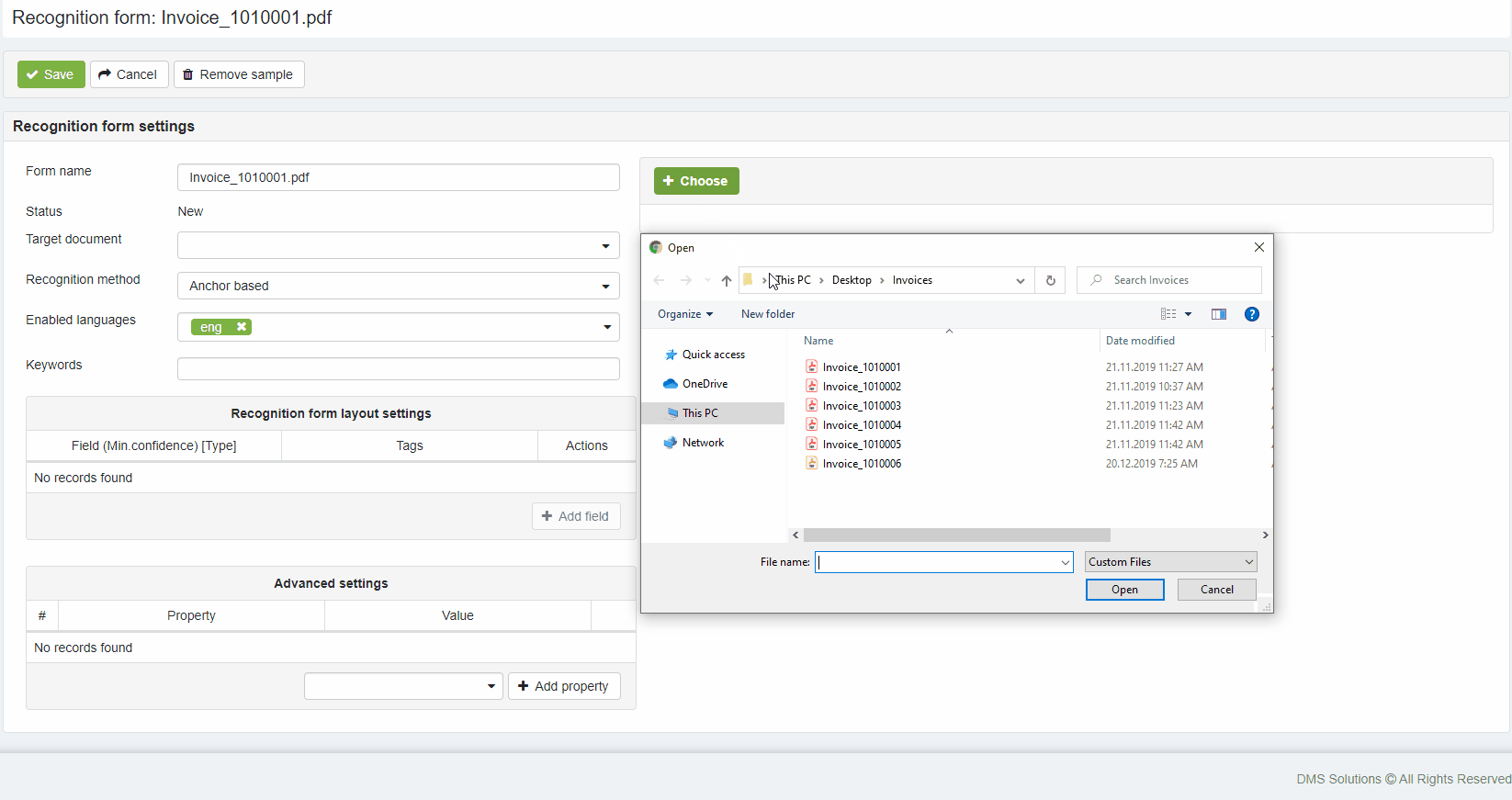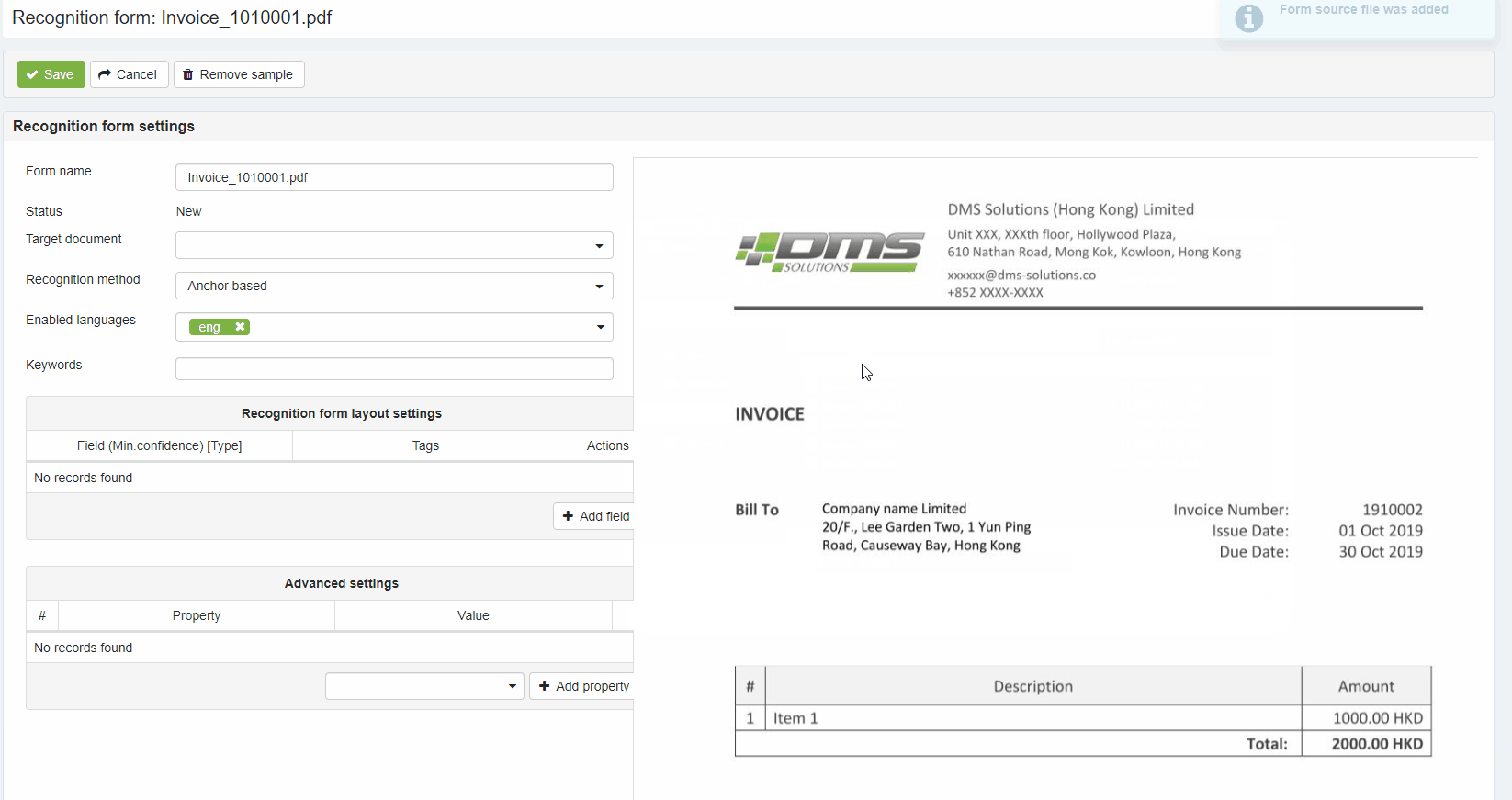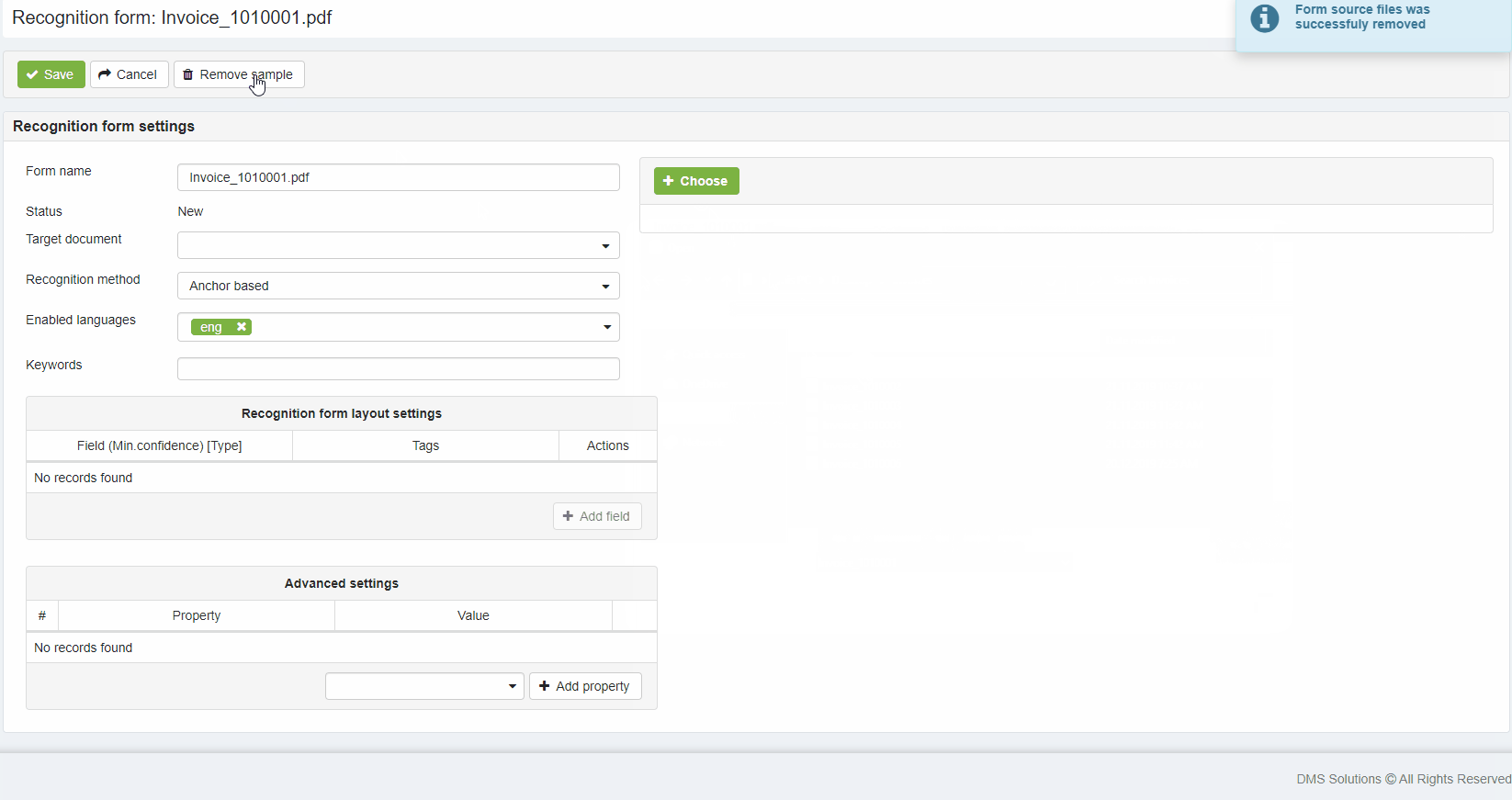
Recognition form layout settings
Recognition form layout settings area used for defining document layout and tells elDoc IDP system which data has to be extracted from the document. To begin with layout settings press the Add field button to add field what will add new field to the layout settings area.
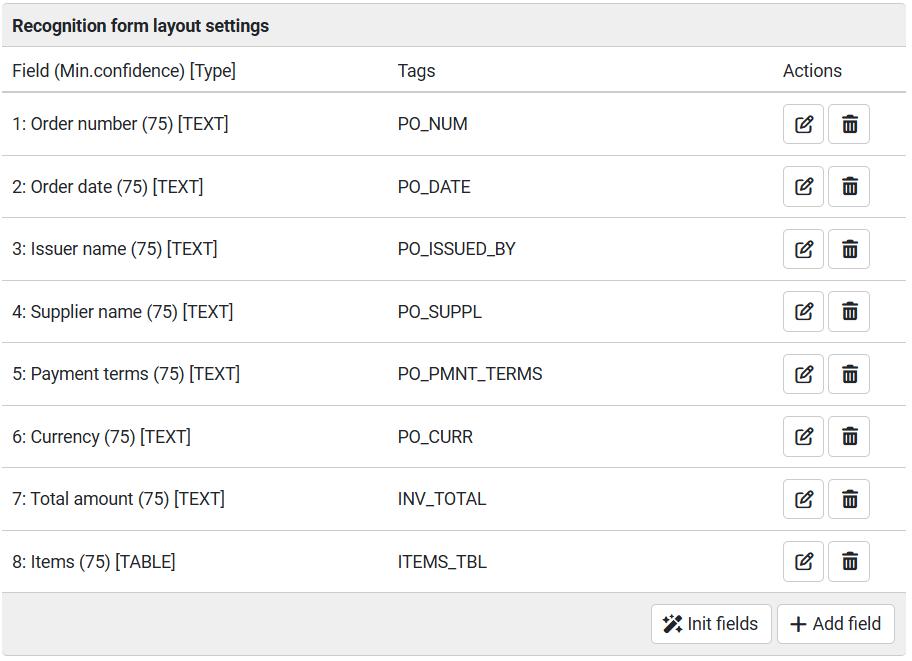
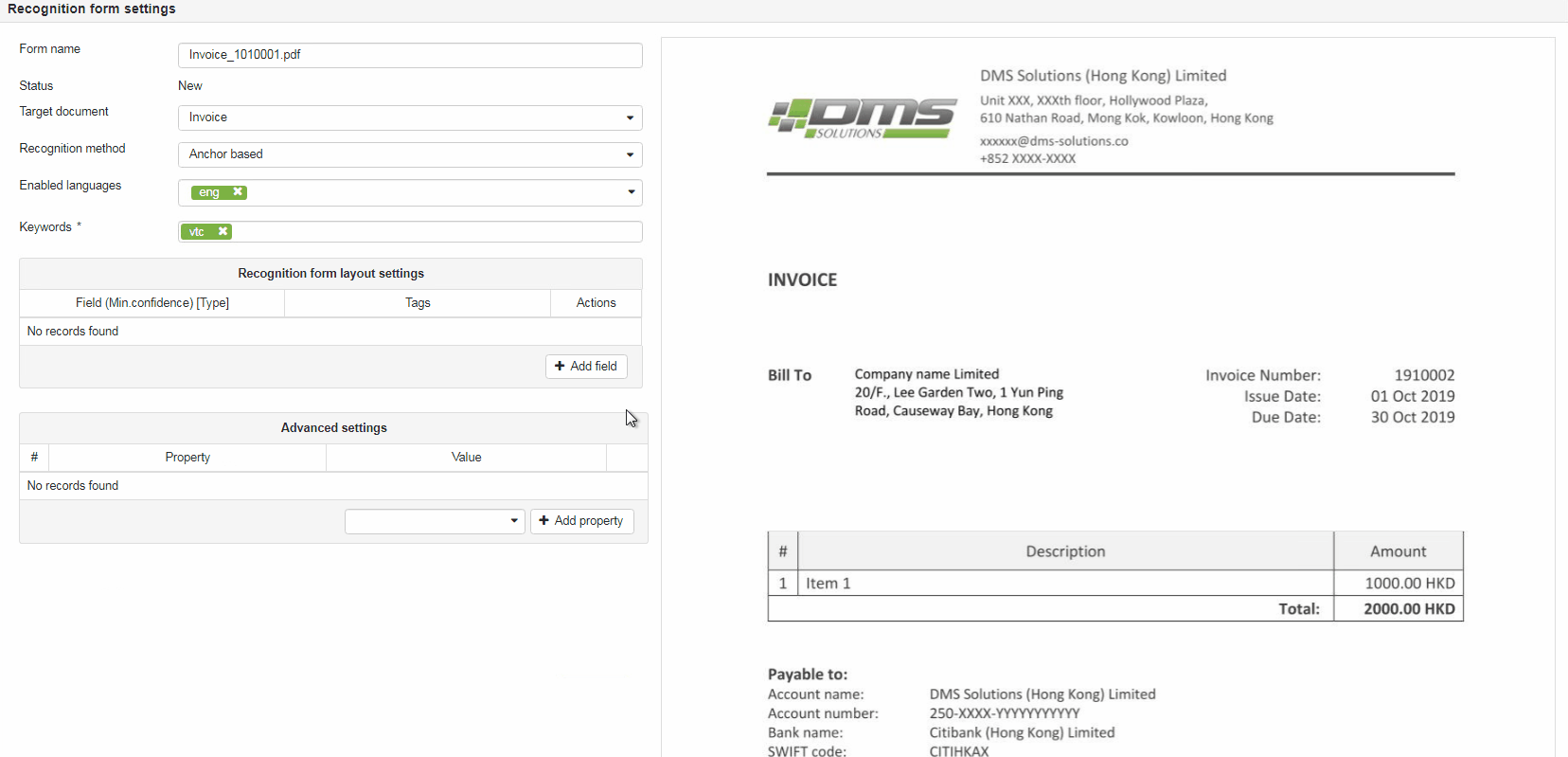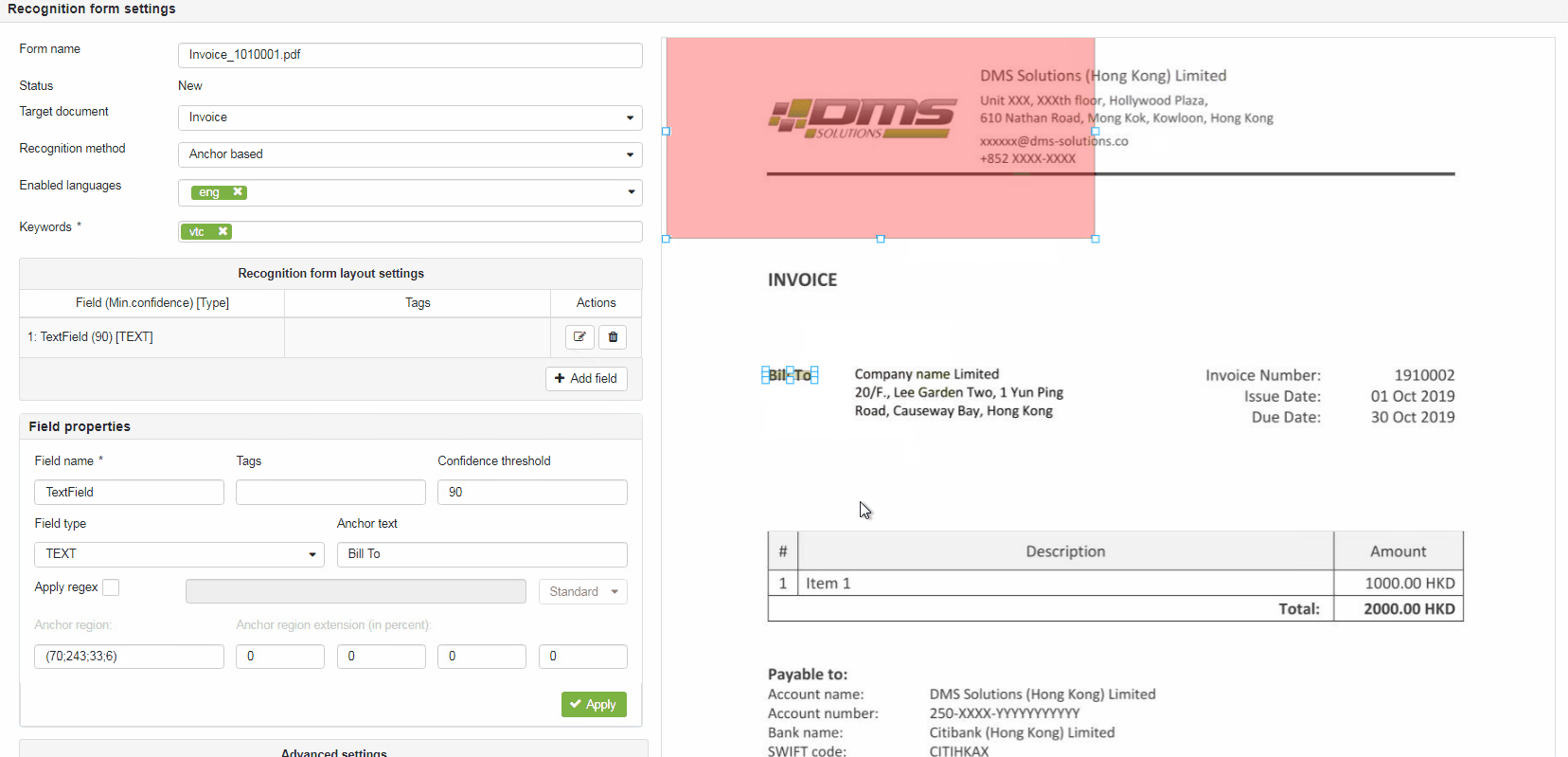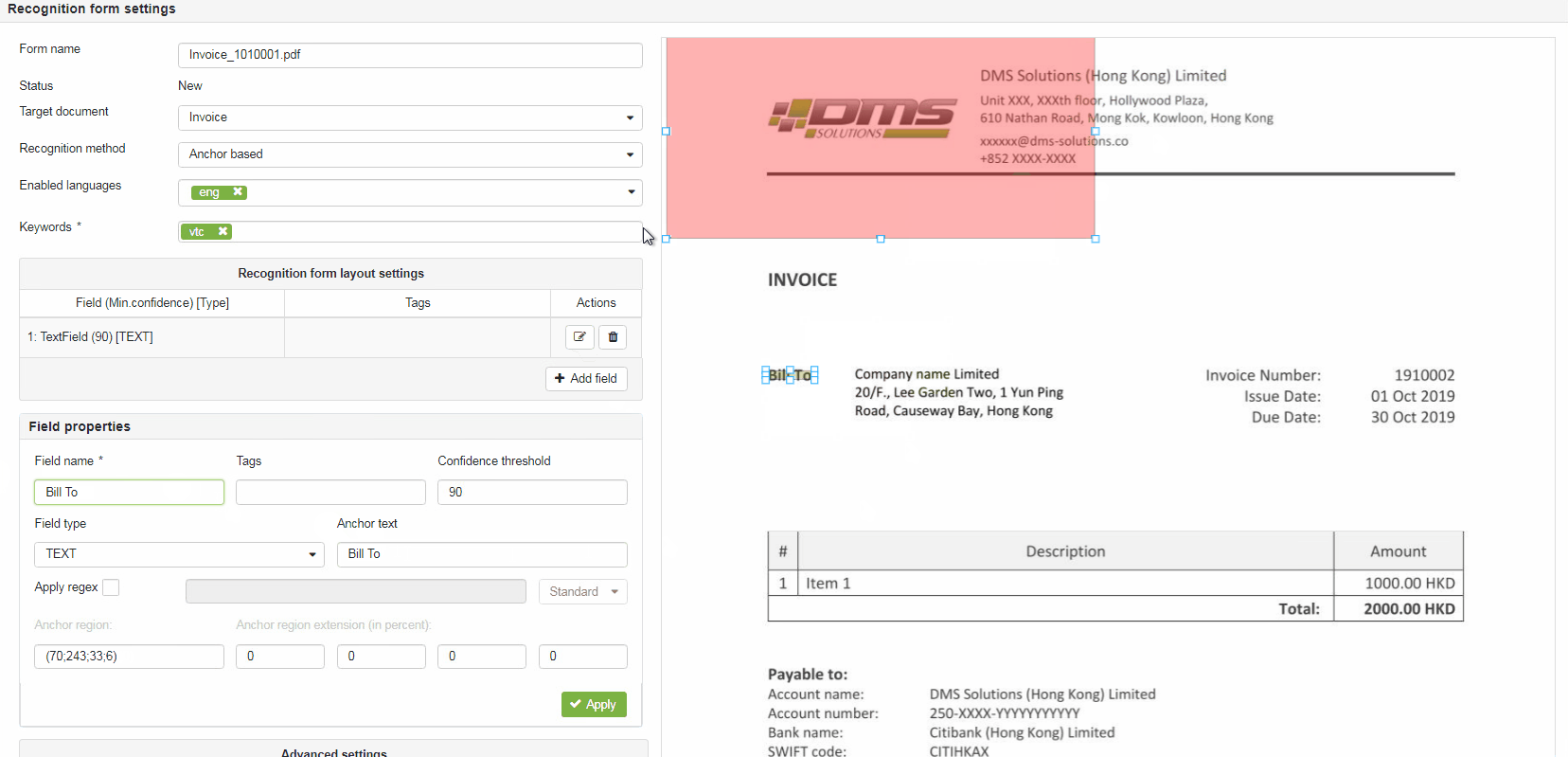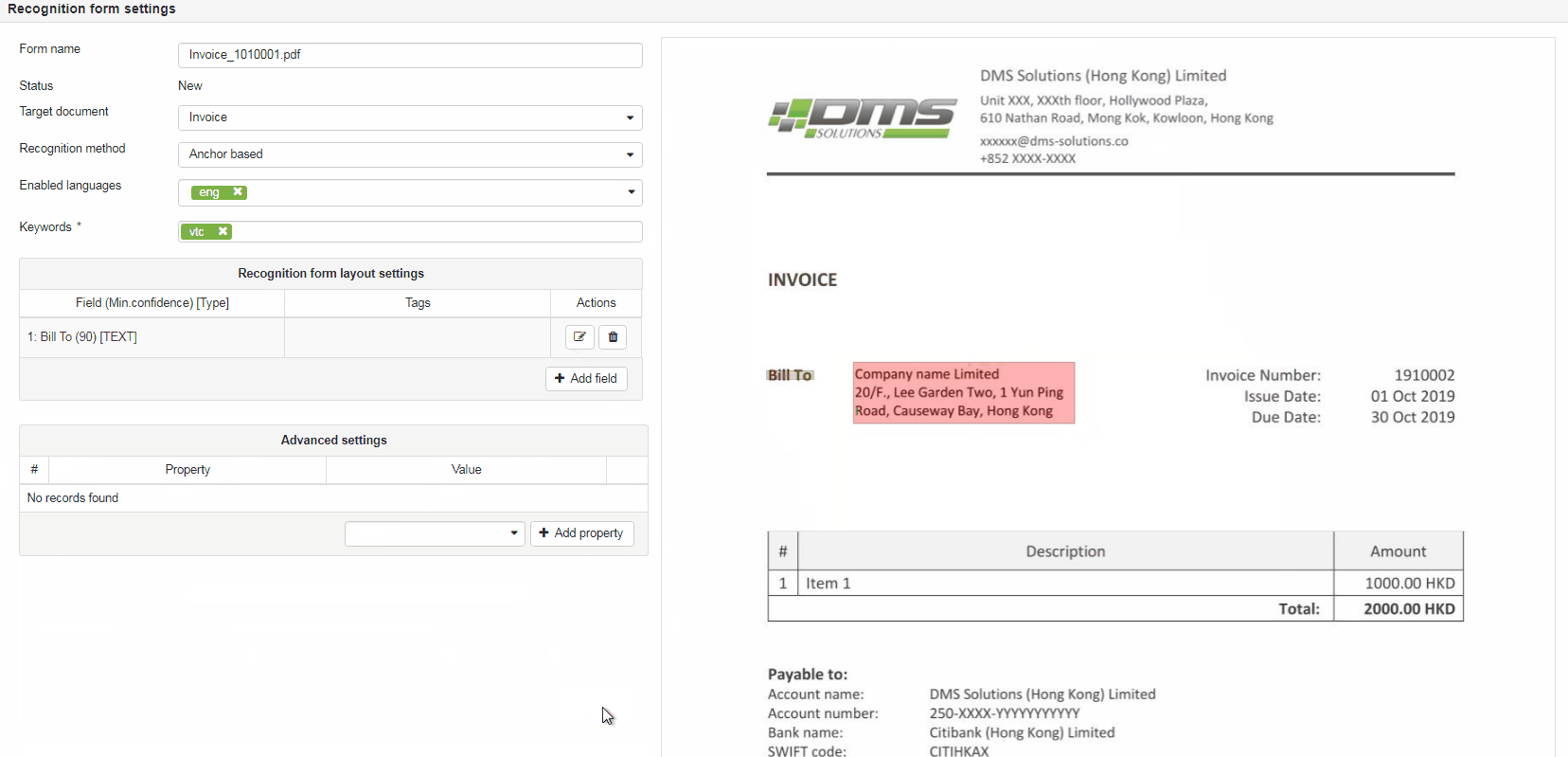
Pressing the +Add Field button also adds 2 rectangular markers on the Document sample preview area that should be mapped (marked over) to the field value region (pink filled) and field anchor (green filled).
When AI functionality is enabled, the Init Fields button is shown. It triggers the initial detection of document fields.
Field properties
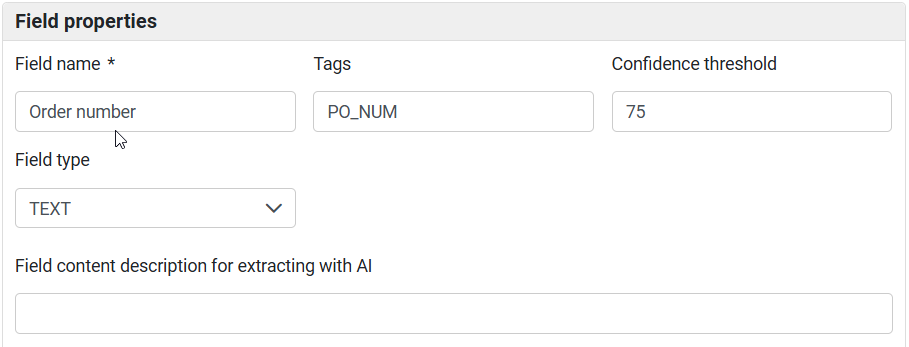
Field name – defines user-friendly field name which describes the value which should be extracted from the document (e.g. InvoiceNumber, IssueDate, TotalAmount etc.)
Tags - defines field tag(s) for programmatic access to the retrieved values via API. In case Conversion phase is enabled for this RecoForm (Target document is set) tag(s) should match with the respective tag(s) on the Document form defined via "Document form -> Form builder" page.
Confidence threshold - defines desired min. confidence level for the field (in percentage from 0 to 100). For the critical fields it is recommended to set value above 85-90. For the optional fields this value can be set to 0.
Note
Confidence threshold is one of the most important measurement used by the elDoc IDP system to decide on the document quality and further processing route for the document. This parameter works in the following way: during the IDP phase confidence level of the retrieved from the document data for this field is compared with the defined Confidence threshold. In case confidence level is below defined confidence threshold - document is routed to the validation stage by the elDoc IDP system.
Field type – defines type of the field. By default it is set to "TEXT".
- TEXT - regular text field.
- OMR - stands for (Optical Mark Recognition) and defines fields with optical marks in form of check-boxes and circles.
- TABLE - defines table field and applicable for locating and capturing the data from tables.
- IMAGE - image type field allows to extract image from the document.
Field content description for extracting with AI - Specifies the field content description used by AI/LLM models to identify, locate, and extract the field’s value from the document.
Anchor text – (shown for Anchor based recognition method) defines field's anchor and should contain value (text) exactly as it mentioned on the Document sample.
Note
Anchor text field supports as plain text values, as well as regex-based values. Regex-based value have to start with "regex:" prefix (e.g.: value "regex:INV(O|0)ICE" will serve as anchor text for both variants of the labels: INVOICE and INV0ICE).
While moving anchor selection box over the document sample - system automatically captures selected text and focuses anchor selection box exactly to the matching text.
Text field settings

Apply regex – defines whether to apply regular expression for the field value partial data extraction (e.g. only numbers without symbols, etc.) by entering regular expression into input field next to the checkbox. The following regex types are available:
- Standard - uses standard regex syntax rules. Named capturing-group should be used with the "value" name, e.g.: "(?<value>X)", where X is the target value which is to be stored as field's value (see more details on the Recognition tuning page).
- Bitap - uses embedded Bitap syntax rules (available only for Regex based RecoForm types). Bitap allows to extract partially matched data from the documents, which matches the defined pattern (with the defined number of mistakes). Bitap supports the following syntax:
- \d - digits, [0-9]
- \D - non-digits, [^0-9]
- \x - letter characters, [a-zA-Z]
- Example: in order to capture text "HKD235.90CR" from the document the expression "HKD\d\d\d.\d\dCR" is to be used with number of mistakes 1 or 2 (depends on the specific case). Using such settings will help to capture values like: "HKO235.90CR", "HKO235.90C", etc.
Table field settings
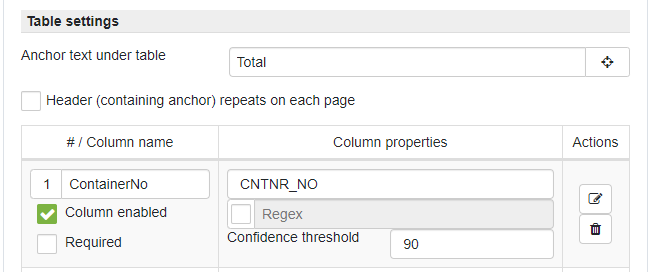
Anchor under table - defines field or text which indicates table end
Header (containing anchor) repeats on each page - defines whether table has a header (with the marked anchor) which repeats on each subsequent page.
By using columns management controls - columns can be added for the given table. Columns have the same parameters as a regular text fields: Name, Tags, Regex and confidence threshold.
Column enabled - marks that column is enabled and should be displayed on the interface and available via API. Intermediate columns which are not required to be captured and displayed can be disabled.
Required - marks column as required, what means each row in the given column has to have a value, otherwise document will be marked for validation.
OMR field settings
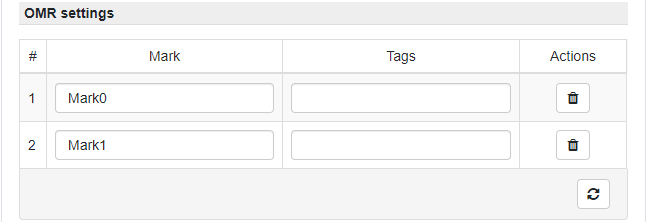
Detect marks - button runs automatic detection of the check-marks in the selected region on the document sample.
Delete - button deletes check-mark for which it was pressed.
Check-marks table provides controls for defining check-mark field name and its tag(s).
IMAGE field settings
Image field type has a standard settings similar to text field.
NOTE: best quality is achieved when processing machine-generated PDF-files, in such case elDoc IDP extracts original image stored in the PDF. When processing an image-based files - image is extracted from the pre-processed source file, as such it is returned as black-and-white (this is a limitation in the current version which will be improved in future versions).
Misc settings
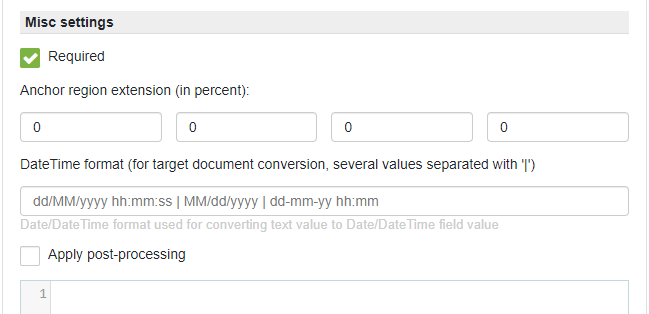
Required - marks field as required. Required fields must always have value on the document. In case field marked as not required - means that field is optional and can be absent on the document or its value can be blank.
Anchor region extension (in percent) - defines percentage for extending the area for searching the anchor relatively to its position defined on the document sample. Has the following order from left to right: Top, Right, Bottom, Left. By default has the following values: Top (180%), Right (25%), Bottom (180%), Left (25%).
DateTime format (for target document conversion, several values separated with '|') - defines date/time format(s) for the field in case current field captures text which represents date/time value. Used when conversion is enabled for the given RecoForm and target field is of the date/time format.
Apply post-processing - defines whether to use field post-processing using JavaScript code (see Recognition results post-processing page for more details).
Field setup (manual) for anchor-based method
Multi-page recognition forms setup
Uploading a multi-page document sample allows to setup a multi-page recognition form. All steps for fields setup on several pages are the same as mentioned above.
Additionally settings listed below are available for pages after 1st page:

Apply a page-break before processing this page - this option works in the following way:
- when this option is enabled all fields defined on the current page are to be searched / located by the system from the new page of the document. As such all fields defined on the page with this option enabled behave like they were located on the first page.
- when this option is enabled for the specific page and no fields are defined on that page, but for previous and next pages fields defined - while processing documents system skips page on the target document in order to reflect page order of the multi-page recognition form. Otherwise system uses fields from the next page of the recognition form in order to locate them on the target document pages one-by-one.
Post-processing settings
Post-processing settings area provides functionality for defining post-processing code for the recognition results captured using the current form. For more details on the post-processing functionality see Recognition results post-processing page.
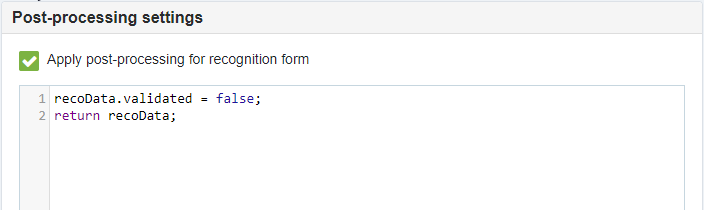
Apply post-processing for recognition form - defines whether to apply post-processing for the document recognition result when it was matched using the current RecoForm.
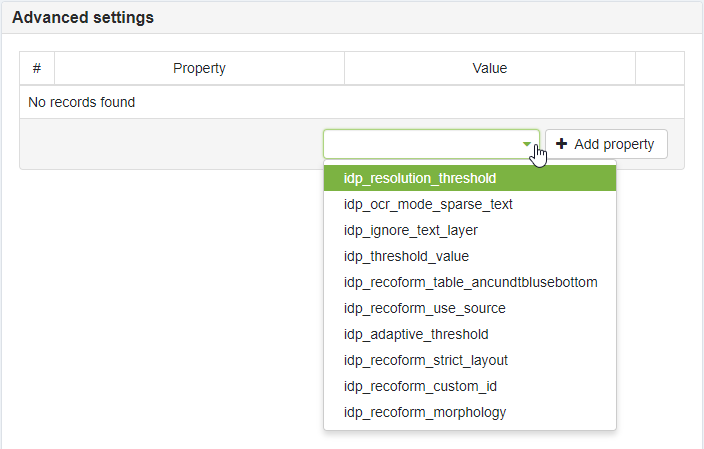
Advanced settings
Advanced settings area provides functionality for adding/editing/removing advanced settings for the RecoForm. For more details on the advanced settings see Advanced recognition settings page.
Last modified: April 16, 2026